Strategic Alignment
AIM.in's vision is AI-first B2B marketplaces. Every AIM vertical will deploy AI agents for:
- Supplier matching
- Quote generation
- Negotiation assistance
- Order processing
- Customer support
AgentOps is the infrastructure layer that powers all of them.
Integration Opportunities
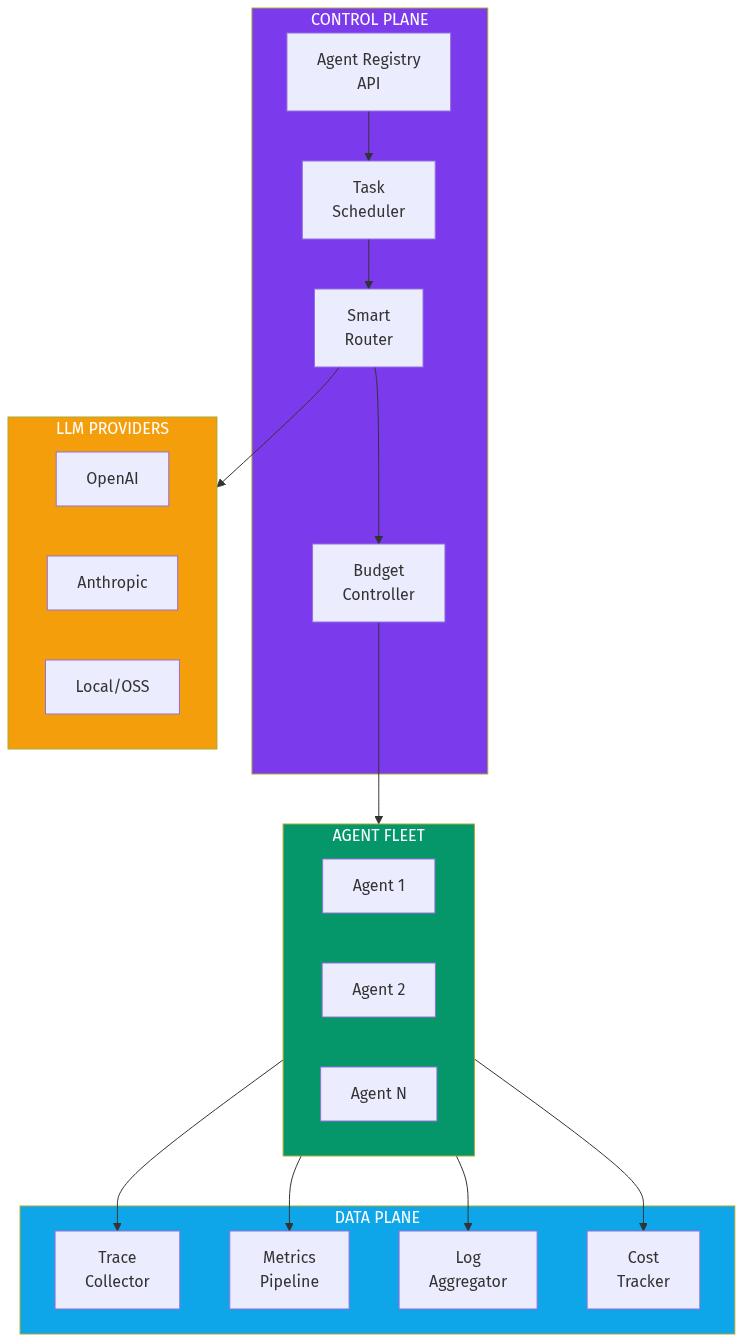
Shared Agent Registry
- Common agent definitions across AIM verticals
- Reusable components (pricing agent, availability agent, etc.)
Unified Cost Tracking
- Single dashboard for all AIM AI spend
- Cross-vertical optimization opportunities
Compliance Framework
- One compliance certification covers all verticals
- Shared audit logging infrastructure
Build vs Buy
This is infrastructure that:
- Benefits from scale (telemetry analysis improves with data)
- Requires specialized expertise (distributed tracing, cost optimization)
- Has standalone market value (can be sold beyond AIM ecosystem)
Recommendation: Build as standalone product, use internally first.
## Mental Model Deep Dive
Zeroth Principles Applied
What axioms are we questioning?
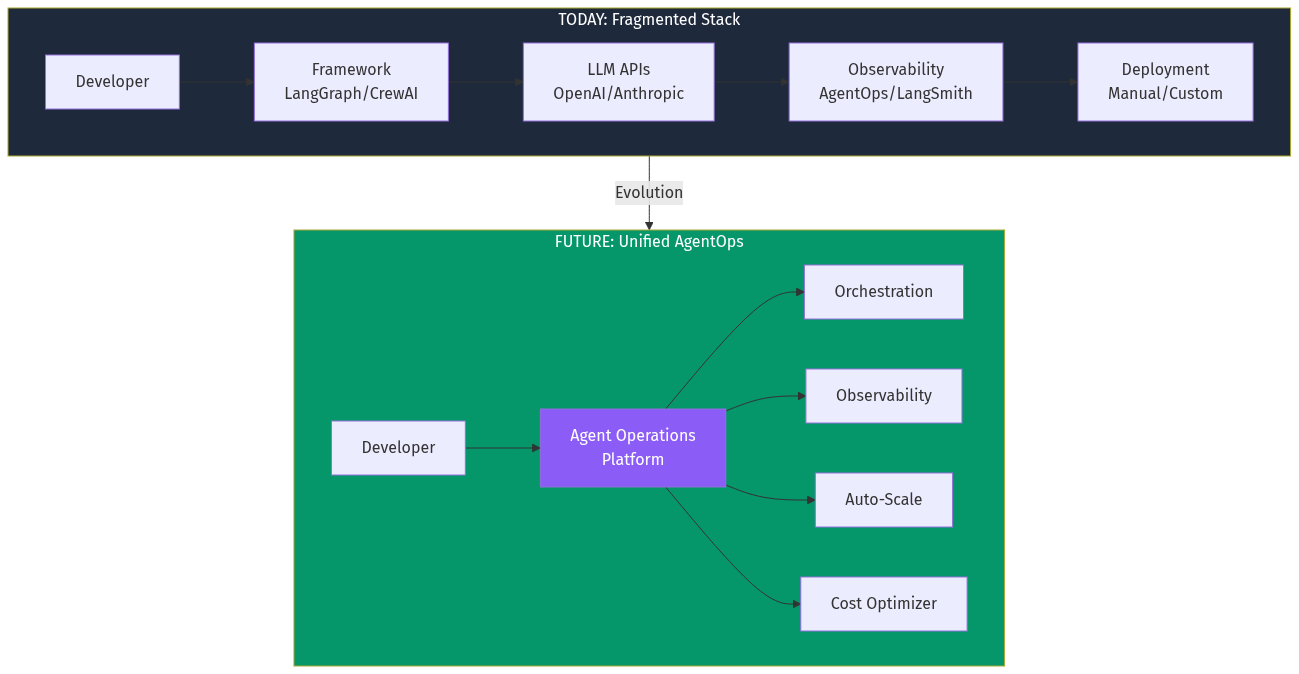
"Developers must define agent workflows" — No. Models are now capable of self-orchestration. The Cord experiment proves agents can decompose goals into coordination trees autonomously.
"Observability and orchestration are separate concerns" — No. They're deeply intertwined. You can't optimize orchestration without observability data. You can't make observability actionable without orchestration controls.
Distant Domain Import
What field has solved similar problems?
Container orchestration (Kubernetes) solved:
- How to deploy and scale distributed workloads
- How to route traffic intelligently
- How to handle failures gracefully
- How to provide unified visibility
Agent operations is container orchestration for cognitive workloads. The primitives differ (spawn/fork vs pods/deployments) but the architectural patterns transfer.
Financial trading systems solved:
- How to route orders to optimal venues
- How to track costs in real-time
- How to audit every decision
- How to fail safely
Smart routing and cost control patterns from trading systems apply directly.
Falsification: Pre-Mortem
Why would this fail?
LLM providers build it themselves
- OpenAI's Agents SDK could expand to full AgentOps
- Anthropic could bundle operations with Claude Enterprise
-
Mitigation: Multi-provider support is key differentiator
Framework vendors vertically integrate
- LangChain adds deployment and cost tracking to LangSmith
- CrewAI builds full enterprise platform
-
Mitigation: Be framework-agnostic, integrate with all
Market fragments by use case
- Different verticals need different operations tooling
- No horizontal platform wins
-
Mitigation: Start with one vertical, expand
Agents don't go mainstream
- Enterprise AI adoption slows
- Agents remain niche
-
Mitigation: This contradicts all market signals; low probability
Steelmanning: Best Argument Against
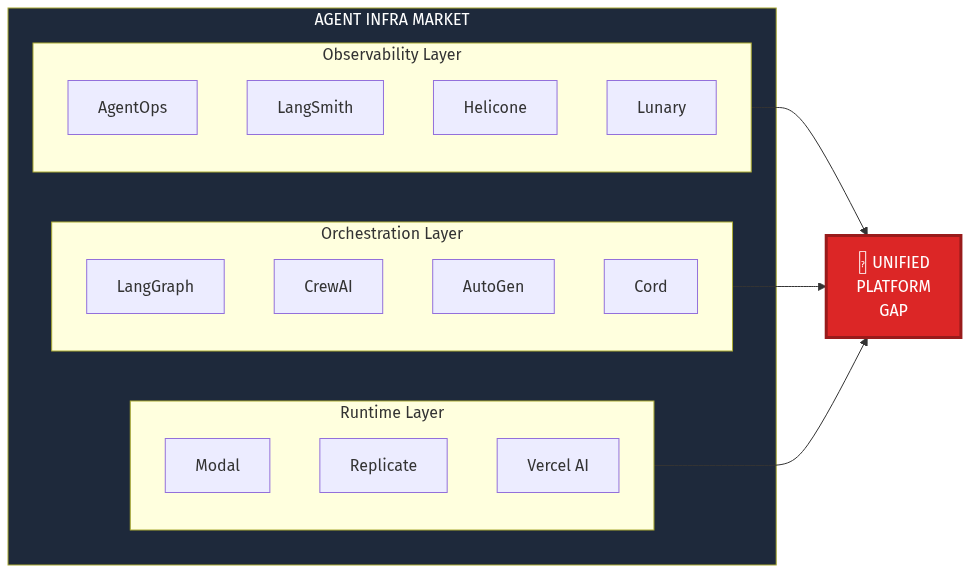
"Existing players will merge and integrate faster than a new entrant can build."
LangChain (LangSmith + LangGraph) + Helicone's routing could combine to create a full-stack solution. They have funding, users, and brand recognition.
Counter-argument: Their architecture emerged from different starting points. LangSmith was built as a debugging tool, not a control plane. LangGraph was built as a framework, not a platform. Integrating them requires rebuilding the core — not just connecting APIs. A purpose-built platform has the advantage.
## Verdict
Opportunity Score: 8.5/10
Strengths
- Clear market pain with measurable ROI
- Timing is perfect (model capabilities just crossed threshold)
- Data moat potential is strong
- Direct applicability to AIM ecosystem
Risks
- LLM provider vertical integration
- Framework vendor expansion
- Requires significant engineering investment
Recommendation
Build. Start with observability + cost tracking (immediate pain), add orchestration (differentiation), then enterprise features (monetization). Open-source the core SDK to drive adoption. Target 100 enterprise customers in Year 1 with $5M ARR.
The agent operations layer is inevitable. The question is who builds it.
## Sources